一个好用的 overdraw 分析工具
移动设备的性能瓶颈
谈到性能问题,无非从 CPU/GPU/内存/本地IO/网络IO来入手分析,巧妇难为无米之炊,善用分析工具是基础要求。GC、DrawCall已经被说滥了,Unity自带的Profiler、各类抓帧工具也比较成熟。本文针对 Overdraw 这个容易被忽视、但尤为致命的移动端性能瓶颈,提供一个好用的分析工具。帮助大家快速、准确地定位问题,以及还需要优化多少。再也不需要凭经验口口相传、凭肉眼一次一次查看。
如果没有这个工具,你将一遍又一遍的重复回答这个问题:下面哪一张Overdraw能够在三档机上以60FPS运行,还需要优化多少?
首先揣测一下Overdraw为什么被忽视。
1、PC时代这个问题通常不是瓶颈。人有惯性思维,低估了PC和手机硬件结构差异;
2、这部分损耗没有直接显示在Profiler工具性能报告中(因为难以量化)。
再说下为什么致命。概括来说,手机显存采用共享内存方式,造成显卡填充率受限。而Overdraw和填充率成正比。
首先分享一张现代移动设备的硬件架构图。老手做性能优化的时候,一方面要看各种Profiler,另一方面要结合硬件能力进行思考,不能只依赖现成工具。
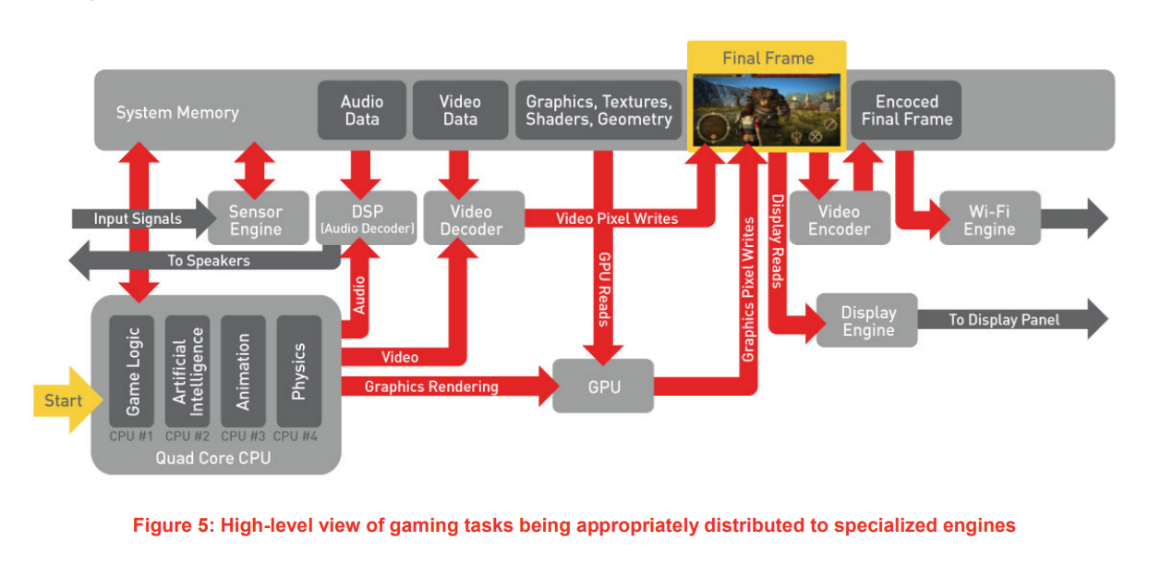
可以看到,和PC有显著不同的是,移动设备没有独立显存,只能和其他系统共享带宽。即每次访问 framebuffer 时,都要从拥挤的公共带宽上从内存中取数据。透明图的渲染又是一层一层进行的,因此要一遍一遍的读写 framebuffer,这不就砸蛋了吗。下面是稍微严谨的分析。
填充率的衡量
什么是GPU填充率。
GPU每秒可写入或渲染的像素总数。不同厂家的计算方法不完全相同。
实际能达到这么高的数值吗。
不能。原因已经解释过,硬件架构决定。为什么是这个架构?因为省钱。
填充率估计公式。
填充率 = 总像素数 x Shader复杂度 x Overdraw
Unity 最新的官方文档也介绍了这个公式,并告诉大家一个评估是否填充率受限的方法:
game run faster if you decrease the display resolution? If yes, you are limited by fillrate.
可以发现Overdraw和填充率呈正比。优化总像素数很简单:把输出分辨率调小到1334x750这个级别,剩下交给硬件去做插值到1080p的屏幕上即可。Shader的优化也有明确的目标:减少Pass,减少ALU运算次数。而Overdraw,只能含糊的说越低越好。
下面就来介绍如何实现一个定量分析Overdraw的工具。
更多关于填充率的细节和一些优化技巧见这一节: UGUI渲染机制
编写 overdraw 分析工具
原理
把高精度采样的结果保存到纹理,利用Compute Shader在GPU中并行计算每个像素点被绘制的次数,传回给CPU统计结果。
大致分为四步:
- 采样:每隔 T 秒将视野渲染到单色纹理。
- 计算:纹理传入GPU,使用 Compute Shader 并行计算各像素渲染次数之和。
- 统计:传回 CPU,统计指标。
- 判定:若当前视野超标,输出日志并暂停游戏运行(这里可自由发挥)。
这里简要介绍下 compute shader:
- 用GPU完成非渲染类任务,可以将计算结果传回CPU。
- 可用范围:桌面端 DX11 及以上,shader model 5。移动端ios使用的是 metal API,安卓使用的是vulkan API 或 openGL 4.3。
- 一个普通的桌面GPU可以同时有2万多个线程(比CPU线程轻量)。
细节
下图是涉及到的主要组件。
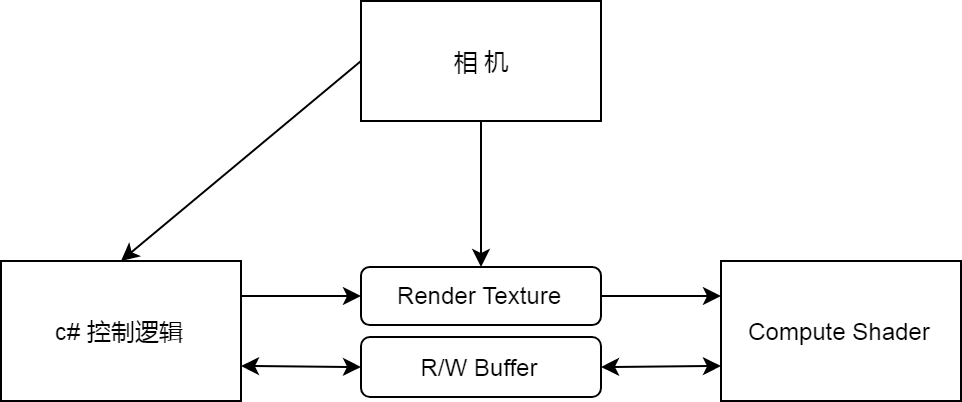
具体步骤:
- 获取宽高等参数,创建采样相机。
- 创建可读写纹理,格式
RFloat 32bit。 - 相机重定向输出到纹理并用自定义shader处理。
- 创建buffer用于存储结果。
- 绑定纹理到compute shader.`
- 绑定buffer到compute shader。
- 划分区块,并行计算。
- 传回结果到c#控制逻辑。
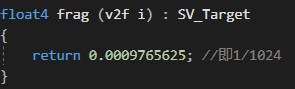
自定义shader只干了一件事:在片元着色阶段,用线性叠加方式,把1024阶采样映射到0~1的区间。
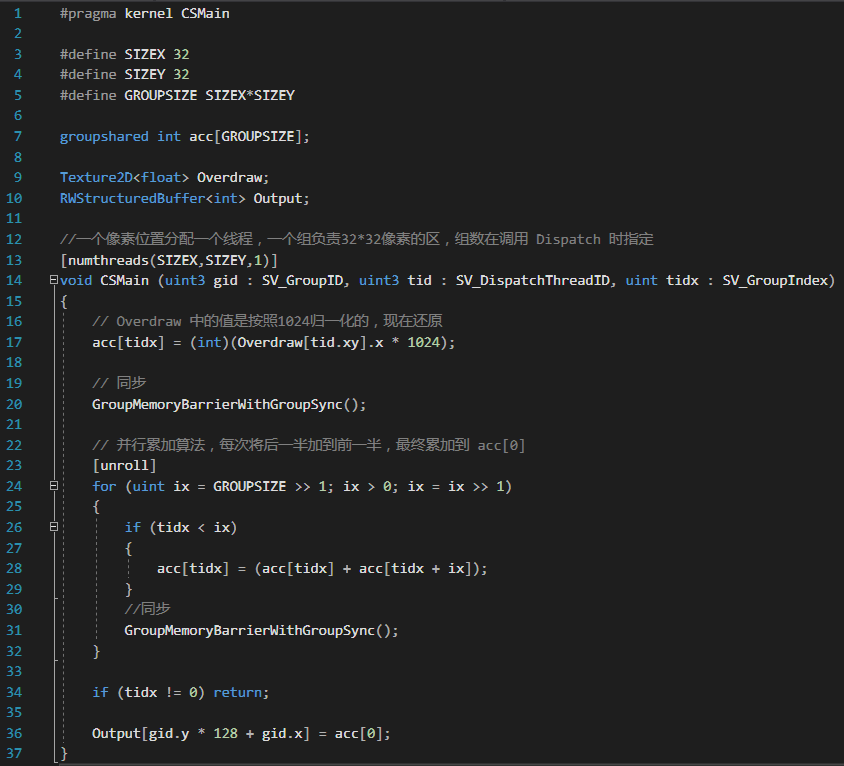
compute shader 里面:一个线程统计一个像素上的次数,32x32的线程组为一个group,有 width/32 * height/32 个group。
Unity C# 如何与 compute shader交互
ComputeBuffer, ComputeShader 类
这里面有相当多的细节。比如采样的数值精度,Rfloat-32是将R通道以32bit浮点数方式存储,有效位是7位,所以这里取1/1024的小数表示时,只保留了7位有效数字。又比如使用内存屏障来同步。又比如参数设置涉及GPU硬件架构,分配多少个线程为一组是一门艺术,需要结合硬件和任务,这里选择 32*32。
总结
通过这种方法,可以定量、无疏漏的排查overdraw问题。并且动态释放的特效也可以被监测到。 下面给出一个简单对比。我们游戏将重绘密度最大值设为5。这个每个项目不同,因为目标机型不同。只要确定一次即可。
粗略比较一下使用该工具前后对效率的提升。
- 时间成本。一个章节的所有关卡,通过人力肉眼检查,10天级别。现在自动运行关卡时检查,10分钟级。
- 准确度。人眼观测结果方差很大,而且难以估计动态特效造成的重绘峰值。现在可以实时、准确的采样,从而定位到问题。
- 修改难度。之前美术同学不知道修改到什么程度才合格,往往要反复修改,经常有挫败感。现在修改时目标明确,可以自测,同时不会因过渡优化而牺牲效果。
本篇就写到这里。compute shader 还可以做很多有意思的事,比如在游戏中用来生成复杂地形,生成漂亮的光照效果。下图是Youtube博主的实验。